
Higgsfield Speak — инструмент для создания реалистичных говорящих аватаров на основе изображения и аудио. Данная нейросеть превращает фотографию в анимированного персонажа с живой мимикой и естественной синхронизацией речи.
🎛 Навигация:
🏠 Главное меню > 🎬 Видео будущего > 📢 Higgsfield Speak
💥 Пошаговая инструкция по использованию инструмента Higgsfield Speak
Настройки модели
Перед запуском генерации рекомендуется предварительно настроить параметры будущего видео.

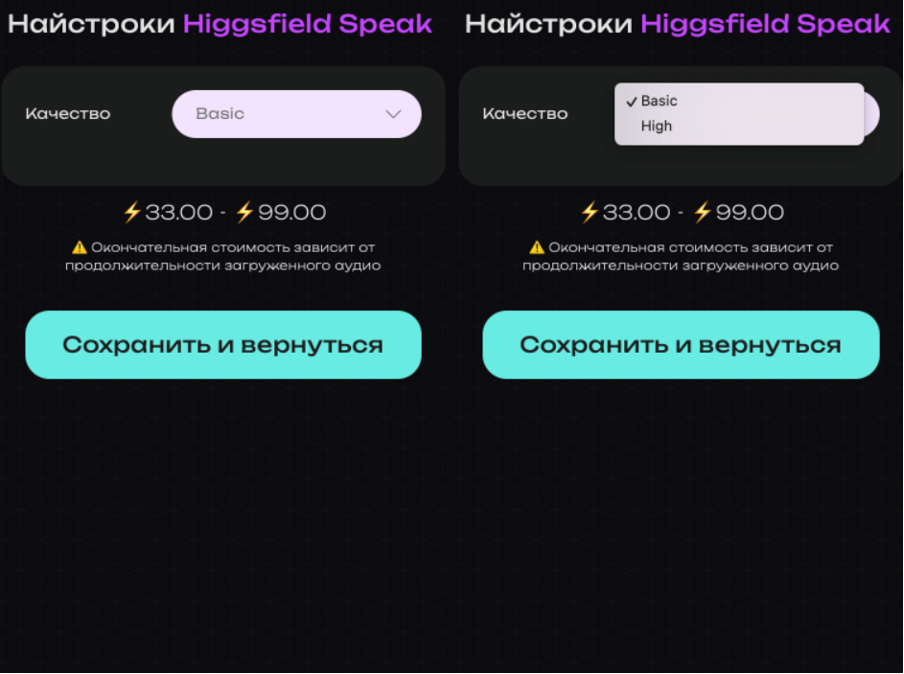
Качество
Вам предоставляется два варианта качества на выбор: Basic и High.
Basic - быстрый вариант для повседневных задач и тестовых генераций.
High - более детальная и качественная генерация, требующая больше времени на обработку.
После сохранения настроек нажмите кнопку «Сохранить и вернуться», затем перейдите к загрузке изображения.
Загрузка изображения
Первым делом для создания генерации вам необходимо загрузить изображение, соответствующее определенным требованиям.
Технические требования к изображению:
- Вы можете добавлять изображение в формате JPEG или PNG
- Требуемое соотношение сторон от 5:2 до 2:5
- Максимальный вес файла - 10 MB
Требования к лицу на изображении:
- Один человек в кадре: на изображении должно присутствовать только одно лицо.
- Положение лица: лицо должно быть направлено строго в камеру, без наклонов и поворотов.
- Реалистичность: лицо должно выглядеть естественно, без чрезмерных эффектов и фильтров.
- Освещение: лицо должно быть хорошо освещено, без резких теней.
- Кадрирование: рекомендуется портретное расстояние съёмки, чтобы нейросеть корректно распознавала черты лица.
❣️ Если загруженное изображение содержит два и более лица, система автоматически определяет, какое из них будет задействовано в разговоре.
Примеры изображений:


Загрузка аудиофайла
После загрузки изображения, вам необходимо загрузить аудиофайл с необходимой озвучкой для вашего персонажа.
Технические требования к аудио:
-
Допустимые форматы: голосовое сообщение, mp3
-
Продолжительность: от 2 секунд до 15 секунд
❣️Если вы загрузите аудио длиннее 15 секунд, оно будет обрезано.
Примеры аудиофайлов:
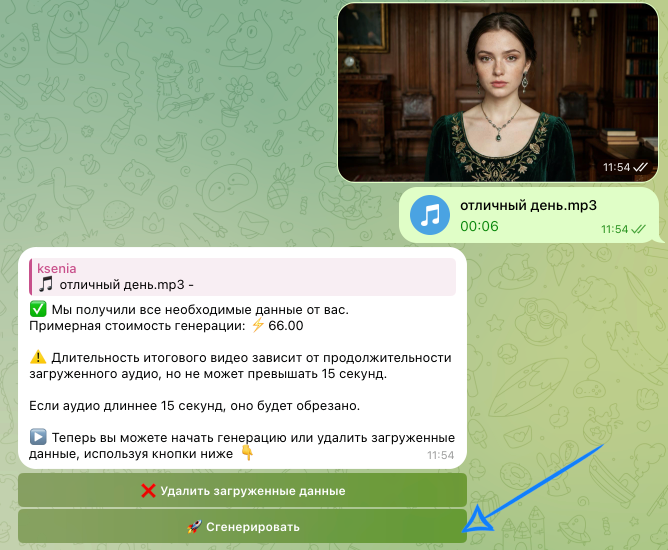
После загрузки всех материалов нажмите кнопку «Сгенерировать» и дождитесь завершения генерации.
Если загрузка материалов прошла некорректно, вы можете удалить текущий запрос и повторно отправить необходимые файлы. Для этого нажмите кнопку «Удалить загруженные данные».
Результаты
Генерации в качестве Basic:
Генерации в качестве High:
Мы искренне надеемся, что эта инструкция поможет вам быстрее разобраться с возможностями Higgsfield Speak и уверенно начать работу с инструментом. Мы постарались изложить всё максимально понятно и последовательно. Помните: результат приходит с практикой. Если что-то не получилось сразу — это нормально. Пробуйте разные подходы, тестируйте идеи, и вы обязательно добьётесь желаемого эффекта! 💛
SYNTX AI: Syntx AI
SYNTX Сообщество: Syntx Community
Блог SYNTX FAMILY: Syntx Family
Служба Заботы SYNTX: Syntx Support